شرکت شیائومی بهصورت بیسروصدا وارد عرصه مدلهای زبانی بزرگ (LLM) شده و از MiMo-7B بهعنوان نخستین سیستم هوش مصنوعی بازمتن خود رونمایی کرده است. این مدل که توسط تیم جدیدی به نام Big Model Core Team توسعه یافته، بهطور ویژه بر روی وظایف سنگین استدلالی تمرکز دارد و بر اساس ادعای شیائومی، در زمینه استدلال ریاضی و تولید کد، عملکردی بهتر از مدلهای OpenAI و علیبابا ارائه میدهد.
مشخصات فنی MiMo-7B
همانطور که از نام آن پیداست، MiMo-7B یک مدل با ۷ میلیارد پارامتر است. با وجود اندازه کوچکتر نسبت به مدلهای پیشرفتهتر، شیائومی ادعا میکند که عملکرد این مدل همسطح مدلهای حجیمتر مانند o1-mini از OpenAI و Qwen-32B-Preview از Alibaba است؛ مدلهایی که هر سه در حوزه استدلال مصنوعی فعالیت دارند.
عملکرد مدل MiMo-7B شیائومی
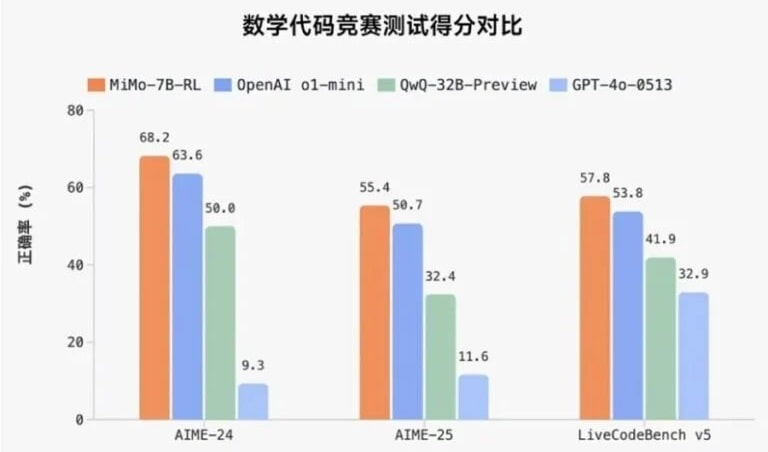
بر اساس نتایج منتشرشده، MiMo-7B در آزمونهای استدلال ریاضی و رقابتهای برنامهنویسی عملکرد بهتری نسبت به مدلهای رقیب داشته است.
- استدلال ریاضی: برتری در آزمون AIME 24-25
- تولید کد: رتبه اول در LiveCodeBench v5 با دقت 57.8٪
- امتیاز قابل توجهی در نسخه 6 همین آزمون با نزدیک به 50٪ دقت
- عملکرد مناسب در آزمونهای عمومی مانند DROP، MMLU-Pro و GPQA با امتیازهای متوسط تا بالا (حدود ۵۰٪)
ستون اصلی قدرت MiMo-7B: آموزش فشرده
شیائومی اعلام کرده است که برای آموزش این مدل، یک دیتاست فشرده شامل ۲۰۰ میلیارد توکن استدلالی تهیه کرده و در مجموع بیش از ۲۵ تریلیون توکن را طی سه مرحله آموزشی به مدل خورانده است.
بهجای استفاده از روش رایج پیشبینی توکن بعدی، شیائومی از هدف پیشبینی چندتوکن بهره گرفته تا زمان استنتاج (Inference) را کاهش داده و همزمان کیفیت خروجی را حفظ کند.
فرآیند پسآموزش و تقویت عملکرد مدل
در مرحله پسآموزش، ترکیبی از تکنیکهای یادگیری تقویتی و بهینهسازی زیرساختها به کار گرفته شده است:
- استفاده از الگوریتم اختصاصی به نام Test Difficulty Driven Reward برای حل مشکل “پاداشهای پراکنده” در یادگیری تقویتی وظایف پیچیده
- پیادهسازی روش Easy Data Re-Sampling برای پایدارسازی روند آموزش
- ساخت سیستم زیرساختی به نام Seamless Rollout که باعث کاهش زمان بیکاری GPU و بهبود سرعت آموزش میشود
بر اساس آمار داخلی شیائومی، این سیستم به ۲.۲۹ برابر افزایش سرعت آموزش و تقریباً ۲ برابر بهبود در عملکرد اعتبارسنجی (validation) منجر شده است.
این زیرساخت همچنین از استراتژیهای استنتاج جدید مثل پیشبینی چندتوکن در محیطهای vLLM پشتیبانی میکند.
نسخههای منتشرشده MiMo-7B به صورت متنباز
شیائومی هماکنون چهار نسخه مختلف از MiMo-7B را بهصورت متنباز در دسترس قرار داده است:
- Base: مدل خام و آموزشدیده اولیه
- SFT: نسخهای که با دادههای نظارتشده (Supervised) ریزتنظیم شده است
- RL-Zero: نسخهای با یادگیری تقویتی از پایه
- RL: نسخه نهایی بهینهسازیشده با یادگیری تقویتی، با بالاترین دقت عملکردی
در دسترس بودن MiMo-7B
این مدل اکنون در پلتفرم Hugging Face تحت مجوز متنباز منتشر شده است. همچنین مستندات کامل و چکپوینتهای آموزشی آن در GitHub برای پژوهشگران و توسعهدهندگان قابل بررسی است.