اوپنآی بهتازگی قابلیت تولید تصاویر با متن خوانا و دقیق را به مدل GPT-4o اضافه کرده است. این ارتقاء چشمگیر، مشکل تولید متنهای نامفهوم و ناخوانا را که در مدلهای قبلی هوش مصنوعی رایج بود، حل کرده و کاربران میتوانند تصاویر پیچیدهتر و حرفهایتری خلق کنند.
چرا این قابلیت انقلابی است؟
✅ متنهای کاملاً خوانا:
- تابلوها، عنوانها و نوشتهها در تصاویر واضح و بدون خطا هستند (برخلاف مدلهای قدیمی که متنهای بیمعنی تولید میکردند).
✅ ویرایش گفتوگومحور:
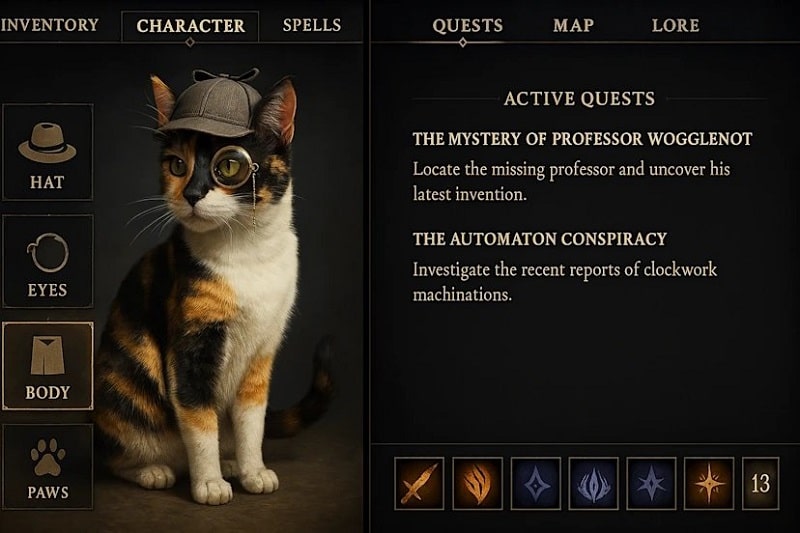
- میتوانید با گفتن جملهای ساده (مثلاً “یک گربه با کلاه کارآگاهی”) شروع کنید و سپس در مکالمه، جزئیات را قدمبهقدم اصلاح کنید (مثلاً “عینک تکچشم هم اضافه کن!”).
✅ ترکیب چندین المان در یک تصویر:
- GPT-4o میتواند ۱۰ تا ۲۰ شیء را در یک صحنه مدیریت کند، درحالی که بسیاری از رقبا در پردازش ۵ تا ۸ شیء مشکل دارند.
✅ استفاده از تصاویر موجود:
- حتی میتوانید یک عکس واقعی را آپلود کنید و از GPT-4o بخواهید تغییراتی مانند اضافه کردن متن یا اشیاء جدید اعمال کند.
محدودیتهای فعلی
❌ متنهای غیرلاتین (مثل فارسی/عربی) هنوز گاهی ناخوانا میشوند.
❌ تصاویر با بیش از ۲۰ شیء ممکن است دچار خطا شوند.
❌ برش ناخواسته حاشیه تصاویر در برخی موارد اتفاق میافتد.
مقایسه با مدلهای قدیمی
| ویژگی | مدلهای قدیمی (مثل DALL·E 3) | GPT-4o |
|---|---|---|
| خوانایی متن | ضعیف (متنهای ناواضح) | عالی (مثل طراحی انسانی) |
| انعطافپذیری در ویرایش | نیاز به تکرار پِرامپت | امکان مکالمه تعاملی |
| پیچیدگی صحنه | محدودیت در تعداد اشیاء | پردازش صحنههای شلوغتر |
کاربردهای عملی
- طراحی پوستر با متنهای دقیق و لوگوهای خوانا.
- تصویرسازی کتابها (مثلاً تولید صحنههای رمان کنت مونتکریستو با جزئیات واقعی).
- ساخت محتوای تبلیغاتی بدون نیاز به نرمافزارهای گرافیکی.
آیا این بهمعنای پایان طراحی دستی است؟ خیر! اما GPT-4o ابزاری قدرتمند برای سرعت بخشیدن به خلاقیت و کاهش هزینههای تولید محتواست.
آیا از این قابلیت جدید GPT-4o استفاده کردهاید؟ چه ایدههایی برای کاربرد آن دارید؟